Editorial note: A version of this blog post was previously published in the JISC IE Technical Foundations blog.
On Tuesday of this week, UKOLN convened a group of invited experts to discuss aggregation in the context of the Resource Discovery Taskforce's vision. The Resource Discovery Taskforce (RDTF), a joint JISC / RLUK venture, has summed up its vision:
UK researchers and students will have easy, flexible and ongoing access to content and services through a collaborative, aggregated and integrated resource discovery and delivery framework which is comprehensive, open and sustainable
Given the limitations of time and resources, and with a firm intention to make a real contribution, the RDTF has decided to focus on aggregation of metadata as a means to progressing the vision. There was some debate at the meeting about the extent to which aggregation is something worth focussing on, and a general concern that this not become an end in itself, rather than a means to an end. We agreed to use the phrase 'aggregation as a tactic' as a way of characterising the proper relationship of this approach to the vision, and steered the remainder of the meeting to address aggregation from a mainly technical perspective. To get the ball rolling, I introduced a slide wherein I attempt to list possible reasons for aggregating data:
- to address systems/network latency - a cache
- for ‘Web Scale concentration’
- ‘gaming’ Google - raising ‘visibility’ of content
- network effects if user facing services also developed
- to showcase (e.g. scale & nature of OER in UK)
- to create middleman business opportunities
- as infrastructure to support locally developed services
- as an approach to preservation
This was discussed at some length, and we agreed that some other reasons could be added to this list:
- for economic reasons - e.g. to achieve economies of scale through storing & managing metadata in one place, implying that the aggregation becomes the sole source of a given metadata record
- to add value to the data through processes, especially around data quality, which are impractical or even impossible to contemplate when the metadata is distributed
- to simplify licensing from the point of view of the consumer of the aggregated data
We noted that while the RDTF vision seems to concentrate on metadata describing resources and their provision, other types of metadata, such as user-generated annotations and user attention or activity data, which is also of great potential interest and value might be aggregated advantageously.
The importance of registries to help in the identification and discovery of relevant data was raised.
For the second part of the day we broke the meeting up into three smaller groups, each concentrating on an aspect of the preceding general discussions. Each of these groups, when they summarised their discussions for the whole meeting later, identified issues and made recommendations. Where these are generally applicable (which they mostly are), rather than outline them in the following descriptions of the breakout groups I have treated them together in two sections at the end of this post.
Breakout 1: APIs
This group looked at the role which Application Programming Interfaces (APIs) have to play in an environment of aggregated metadata and related services. It used a spectrum of technological interventions ranging from specific service development to meet a particular need, through to generic infrastructure provision to provide opportunities for others to develop services, and attempted to place classes of APIs on this spectrum:
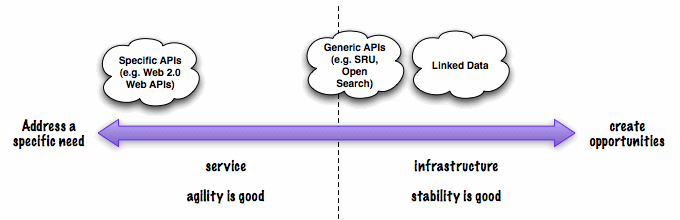
It was agreed that it was important to understand this distinction, and to be equipped to judge where to 'draw the line' between meeting specific requirements and investing in capacity for future innovation. There is clearly a tension between agility - which is a feature which becomes more desirable as one moves along the spectrum towards those servicing users' requirements, and stability which is necessary for infrastructure to be trusted. Part of the purpose of APIs is to help to manage this tension.
APIs are for developers, and so APIs on aggregations must be highly usable from the point of view of a developer. Focussing on the need for aggregations to expose APIs so that services can build upon them, this group made some recommendations (included in the general recommendations at the end of this post) about the sorts of general features an API should exhibit. In general, it was agreed that an API on an aggregation must be more convenient, from the point of view of a developer, than going directly to the individual sources. Leaving aside simple issues of network latency, in a possible Linked Data future where data is commonly openly available, the aggregation and its API must not become a barrier to building services and adding value to data.
This group also discussed the issue of federation of aggregations - where one aggregation feeds another. There are serious engineering issues with this kind of federation which require better understanding.
Breakout 2: Aggregation as tactic
This group decided to start by looking for "prior art" - examples of successful uses of aggregation as an tactic to improving resource discovery. With this approach, it was suggested, it would be possible to identify stakeholder groups which are already 'bought into' the idea of using aggregation as a tactic in this way, which ought to be easier than convincing people from scratch. The trick would seem be to be to identify a shared service which could be developed upon an aggregation of metadata, and which they could recognise would be beneficial to them. Examples of successful aggregations were identified and included:
- Copac (aggregated records from National, Academic, and Specialist Library Catalogues)
- SUNCAT (a national serials union catalogue)
- Worldcat (a global, aggregated library catalogue)
Echoing an earlier point, the group suggested that the value in aggregation as a tactic comes from the ability to normalise metadata into some sort of canonical form. This aspect of the aggregation adding value to the data it aggregates is crucial if the source record holders are to be persuaded to participate.
The group suggested that JORUM's role in supporting the national (and global) Open Educational Resources (OER) movement was very much in line with this thinking: that JORUM enhances discoverability of OERs created in UK institutions, while simultaneously offering the potential for long term archiving (preservation). Again, the importance of the registry becomes apparent this group suggested, with JORUM likely to become important as a service providing identification and 'provenance' services.
The group discussed the idea of concentrating on one particular domain, such as geography, on the grounds that this could then be built out to an extent that other domains would become interested once they had seen what has been achieved. The counter to this argument was a suggestion that it might be better to consider a range of resource types including scholarly communications (bibliographic data), learning materials, repositories, spatial/geographical data and multi-media.
It was also noted that the 'aggregation as a tactic' argument might apply to self-archiving and Open Access - which has similar arguments as for JORUM and OERs.
It was suggested that this was leading to a set of tactics which would help content providers get over a 'fear' of aggregation, and of encouraging them to open up from a position of 'data ownership'. It was also recognised that once this is achieved, aggregation as a tactic creates opportunities for 'middle-men' to add value through new services building on top of the aggregation.
Interestingly, this group suggested that aggregation as a tactic might be a short-or-medium-term tactic, that the 'end game' would be to dis-aggregate content back to source. At this point, the remaining infrastructure would be of the 'registry' type, helping to locate data at source.
Breakout 3: Build better websites!
The emphasis of this session was about advising & enabling those who hold source metadata to make it available in an appropriate form. The group identified a number of 'steps' that a content provider might take. These steps are ordered in a system of progressive desirability in a model influenced by Tim Berners-Lee's Linked Data Note:
- make data available in an open form (even using the much-maligned CSV format if necessary)
- assign and expose HTTP URIs for everything, and expose useful content at those URIs
- publish as XML
- expose semantics
It was noted that these steps do not demand that a provider should work their way through them sequentially - it is perfectly acceptable and even desirable to jump in at step 4 - however this might represent a significant barrier to some, so steps 1-3 are there to give content providers a chance to engage comfortably.
Barriers specific to this model being adopted successfully include the issue of securing vendor 'buy-in'. For content providers to support this model, their software platforms need to enable it. This may not be the case at present in most cases. Also, specific skills in Linked Data are not so widespread in these sectors (yet), and an appreciation of and support for Linked Data is not common among senior managers. It was recommended that JISC create some political momentum around this, perhaps devising a convincing argument for senior management. It was also suggested in this breakout group that RDTF should provide a central resource (guidance & possibly infrastructure) for hosting data, especially for smaller organisations.
This approach was summed up as a description of a potential glam.ac.uk where glam is galleries, libraries, archives and museums.
General Issues
- Lack of technical expertise in libraries, museums and archives. This applies most strongly in respect of the 'build better websites' model, but is also true more generally, especially when the long-tail of glams is considered.
- Business case, or possible lack thereof. The content providers need to see a clear benefit before committing to the cost involved in supporting the aggregation of their data.
- Content providers often show a reluctance to make data openly available on the grounds that they may expose poor quality which reflects badly on them
Recommendations
The various discussions during the meeting gave rise to a number of suggested recommendations. It should be noted that these are based on a few short hours of discussion - however the experience of the group which made them is considerable, so I hope they might be considered seriously.
- The 4 step model for advising/supporting content providers in opening up their metadata
- The RDTF should fund aggregation projects that demonstrate value in these steps
- e.g. "Tell me how my content is being used"
- Providers should provide a semantic sitemap leading to a data aggregation. This could be RDF or XML
- Providers should expose the schemas they use (whether their own schemas or links to established schemas)
- Aggregation services should provide guidance to content providers about schemas to be used (a registry of recommended schemas would be a useful component)
- Aggregators should not reject data on basis of schema used by the content provider - aggregators should be prepared to accept anything
- The RDTF should (in partnership with others) seek to engage with vendors of collections/content management systems in the various domains.
- Aggregations should have supported APIs which are attractive to and convenient for developers, offering developer-friendly output formats such as XML or JSON
- Aggregation should be considered, perhaps, as a temporary approach to aiding discoverability. More extremely, a 'just in time' approach to aggregation might be considered.
- A 'cookbook' of design patterns involving aggregation as a technical approach to resource discovery might be a useful thing to consider funding.
- A '2 tier' model of metadata might be worth considering, where one tier is for common, basic description and identification, and the other tier is for more targeted uses.
Many thanks to those who attended and made the meeting a success:
- Peter Burnhill (Edina)
- Hugh Glaser (Seme4)
- David Kay (Sero)
- Andrew Kitchen (Becta)
- Ross MacIntyre (Mimas)
- Andy McGregor (JISC)
- Paul Miller (Cloud of Data)
- Andy Powell (Eduserv)
- Owen Stephens (independent)
- Adrian Stevenson (UKOLN)
- Paul Walk (UKOLN)
- Jo Walsh (Edina)
And thanks to Adrian also for organising the meeting.


Comments
[...] ●
[...] ● http://www.ukoln.ac.uk/jisc-ie/blog/2010/08/19/aggregation-and-the-resou...... [...]
http://inf11briefingoct2010.jiscpress.org/infrastructure-for-resource-di...
Infrastructure for resource discovery « Briefing Paper for eResearch & IE Call – 10/2010
[...] ● The 4 Steps of
[...] ● The 4 Steps of structuring data as adopted by the Resource Discovery Taskforce: http://www.ukoln.ac.uk/jisc-ie/blog/2010/08/19/aggregation-and-the-resou...... [...]
http://inf11briefingoct2010.jiscpress.org/identifiers/
Identifiers « Briefing Paper for eResearch & IE Call – 10/2010
[...] Aggregation and the
[...] Aggregation and the Resource Discovery Taskforce vision [...]
http://blogs.ukoln.ac.uk/newsletter/2010/09/newsletter-for-august-2010/
Newsletter for August 2010 « UKOLN Update
I have limited comments as I
I have limited comments as I think this reflects the discussions pretty fully!
Intro – Economic Reasons – Managing metadata - this begs whether cataloguing of SOME content types might migrate to become an aggregated / shared service function. This was certainly in the minds of some libraries in responding to the SCONUL Shared Services idea.
Breakout 2 – We also mentioned Repositiories UK in the list of current aggregations
Breakout 2 - The list of library examples (Copac, Suncat, WorldCat) indicates that a very large number of institutions have already bought in to the idea of ‘servicing’ an aggregation. Our thinking was that the RDTF programme should exploit this critical mass from Day 1 by working on RDTF Step 3 (Service providers exploit aggregations) in order to prove the RDTF aggregation concept. With Z39.50 we had to wait too long!
Breakout 3 – Who / what would benefit from a central platform? Not just smaller organisations but also anyone with new types of (meta)data but without the local mandate or capacity to curate it; for example – activity data, annotations (and other forms of structured UGC). This would of course make a lot more sense if we had URIs ;)
Breakout 3 - As highlighted by Ross, discussion of BO3 referenced Digital New Zealand, from which there is plenty to learn (some suggested) at the ‘low end’.
Recommendation 2 – So we want to see a couple of projects in the forthcoming JISC call that demonstrate aggregations that incorporate well-formed CSV data? Yes, I think we do!
David
[...] Implementing the
[...] Implementing the resource discovery taskforce vision largely depends on addressing these challenges. Fortunately there are a lot of smart people in the HE community so I fancy our chances. Paul Walk and Adrian Stevenson of UKOLN are managing a project called the IE technical review which has been set up to examine these kind of issues. As part of this project Paul and Adrian pulled together a group of experts to discuss the technical side of the RDTF vision. You can read a summary of the meeting on the IE technical review blog. [...]
http://rdtf.jiscinvolve.org/wp/2010/08/31/addressing-some-technical-ques...
Addressing some technical questions posed by the RDTF vision at Resource Discovery Taskforce
I was sorry to have missed
I was sorry to have missed this, it covers a lot of what we have been thinking about in relation to the ERIS project's work in producing aggregations of content for both the Scottish HE community, but also for the Scottish research pooling initiatives, where we have been working to demonstrate the ability (with the CRISPool project) for creating and managing aggregations of content and data about people and organisations using the CERIF model.
This leads me to the point in my comment, which is to include a benefit of aggregation as being a facilitator of knowledge exchange, and as a means to improve the overall efficiency for those who are dealing with research strategies - especially on a 'horizontal' subject basis, such as research pools, or other research groups.
I enjoyed the day; just
I enjoyed the day; just looking over my notes to see what was not reflected in the more general discussion.
Firstly, the question of whether we are aggregating data or metadata. If the Mission is to provide better (more efficient, more illuminating) discovery of resources, then is it served by aggregating at a metadata-only level? Are we assuming here "open" (under the terms of the Open Definition) metadata, describing resources which may or may not be open?
This issue has caused some frustration around a geodata aggregation and search service that EDINA runs, Go-Geo!, where users see references to resources and notes on how to get access to the data but there may be no payload, e.g. no instant access to data. Meanwhile to meaningfully do the indexing and comparison of resources, the aggregator also needs some access to the structures of the data.
At least half of discovery is de-discovery, e.g. filtering away things the user does not want, using connections between things and hints from user activity to guess at what is not wanted, as much as what is wanted, in search results.
In this case centralisation (aggregation) appears to work pretty well - for example, Google Mail does a much better job of filtering spam than does the mail reading software on my local machine, though both use many of the same techniques (training Bayesian recognisers on a known corpus of spam, looking at black/white/grey-lists etc). Again, to do proper filtering, one really needs to look at the data itself, not just the description of it.
There was a suggestion that aggregation could *help* resolve license incompatibility issues by presenting them all with one face, which sounds interesting, but there is a cost to the aggregator of having to negotiate, record, assess license terms. So it seems to me that open source / open data must underpin a lot of this discussion about aggregation, yet that is not reflected all the way through the picture.
"Aggregation as tactic" is interesting in that it does pre-vision providers of resources becoming publishers, and if there is money to be made in adding value to collections, trying to add the value and return it to themselves as directly as possible - which seems to pull us away from the desire to see aggregation as renewing a "middle-man added-value" model - productive tension, i hope.
There's a certainty this kind work is being done by others, and not only that but at several nested levels - Collections Trust and Europeana for cultural heritage in "GLAM", or DEFRA/Ordnance Survey and the JRC for geographic information. Or just by Google; is repetition helpful, redundancy inevitable? In this sense we could only get this far in a day devoted to "discuss aggregation" rather than "discuss what should happen"; and it entertained me that so much of the technical talk was rather about collective business development - made me wonder if business people talk among themselves about protocols and interfaces.
According to my notes: 1) The
According to my notes:
1) The approach 'glam.ac.uk' (apologies to University of Glamorgan) was actually 'data.glam.ac.uk' (tho' still got domain issues!)
2) There were very favourable comments made about the approach adopted by Digital NZ (http://www.digitalnz.org/) and how about a 'Digital UK'?
Cheers, Ross