Author: Peter Sefton
HTML5 Case Study 9: WordDown: A Word-to-HTML5 Conversion Tool
1. About This Case Study
Target Audience
The main audience for this work is tool developers building authoring systems, repositories and publishing infrastructure for academic documents.
It may also be useful to committed academic authors, comfortable with HTML already and some technical skills, who would be able to install a bookmarklet and possibly run Python code on a Windows machine (i.e., not the broad academic community at this stage).
What Is Covered
This case study examines ways that academic authors working with word processors such as Microsoft Word, the OpenOffice.org family and Google Docs would be able to produce compliant Scholarly HTML5. Due to time constraints, the tool developed for this project handles Microsoft Word documents only, but the principles outlined here apply more broadly.
Word processors are used very widely in academia for all sorts of document authoring. Articles, essays, theses, course materials, and so on, are being produced in huge quantities in Microsoft Word and similar applications in the Higher Education sector. Yet they are not easy to convert to good-quality, clean, semantically rich HTML 5 of the type being discussed in the JISC HTML5 Project.
This is a critical piece of work for the overall project of bringing scholarship to the (semantic) web. If the tools still being used to create academic content do not create HTML natively, then who will do the mark-up? What new tools are needed, if any? This case study will consider these questions, as well as produce some demonstrations of what is possible with the example application, WordDown.
What Is Not Covered
The questions posed above about tools for creating HTML5 are even more pertinent if we are targeting XML for scholarly documents. However, XML is in its teens now, yet there have been no widely available tools produced to create XML for DTDs such as DocBook or TEI that have gained any kind of traction with large user groups. This is an interesting question for the Higher Education sector, but it is out of scope for this case study.
2. Use Case
There are no formal studies of which I am aware that show the usage rates of different academic authoring tools by country or discipline; but it is quite clear that Microsoft Word (along with other word processors) is a very widely used document-creation tool in many, many disciplines at our Higher Education institutions and research organisations. For example, on this study the UKOLN team have requested that case studies be submitted in Word format, using a template supplied by UKOLN. While the template gives the case study documents some structure, using 'Save as HTML...' from Word will not produce good-quality HTML - far from the kind of structured documents that are being produced as exemplars in the JISC HTML5 Project, Word's output is focused on a decade-old approach which tries to match paper formatting.
The format is discussed in an article by the author [1] which notes that some simple transformations can render it into XML, which can be processed by standard parsers. A short excerpt from the HTML produced by MS Word for one of the case study documents illustrates this:

and

There are three main issues with the native format.
- It contains processing information which is foreign to HTML, embedded using a mixture of comments to hide code from being rendered in browsers, and some non-standard mark-up. An example of this is the way it renders lists as a series of paragraphs rather than as an HTML list structure. This is an example from one of the other case studies. Constructs like <!--[if !supportLists] are not part of the HTML standard, although all browsers have evolved to deal with this idiom.
- It is oriented towards looking right, rather than working as a Web page so contains a lot of information about indents and so on that are page-oriented.
- It is very verbose - with span elements and other spurious mark-up appearing as an artefact of the editing process.
There is now in Word a 'Filtered' output which removes much of the worst mark-up but it still does not create documents which are clean, reusable HTML or HTML5.
The use case here is using Microsoft Word in the production of any academically oriented document that is destined for the Web, including articles, theses and other student work, reports, course materials, academically inclined blog posts or other Web pages, and reports such as this one.
3. Solution
The improvement this study proposes to the current approach in using Word to create HTML5 is a tool called WordDown, created for this JISC project. This is a JavaScript application which runs in a Web browser and processes Word documents into clean HTML5. It takes Word's HTML output as an input.
The wiki at the JISC HTML5 Project at Google code[1] covers how to run the application and the basics of how to format documents.
Background to WordDown
The Word 2000 HTML format has been a feature of Microsoft's flagship word processor since the '2000' version, and has been the target of much criticism. At the time it was introduced, it was capable of rendering almost all features of Word documents into a kind of HTML, using a combination of extended CSS formatting and islands of very obscure non-standard mark-up. It was actually not very far away from XML, and could be processed into XML with a small transformation program [2].
The solution presented here revisits the format with modern tools by loading it into a modern Web browser and using the jQuery framework to interrogate various aspects of the formatting. Recent versions of Web browsers are all coded to deal gracefully with the 'mutant mark-up' in Word's HTML output, hiding Word-specific code in comments, because HTML5 parsing rules take account of all kinds of legacy issues like Microsoft's non-standard mark-up.
The application WordDown is inspired by the success of lightweight wiki-style mark-up languages which allow users to create HTML (and PDF in some cases) from simple text files . One of the foremost examples of this class of language is the MarkDown format, used by the Pandoc processing framework. (Peter Krautzberger has a useful introduction to Markdown and Pandoc for academic authors and explains how it may be considered what we might call 'the new LaTeX' for academic authoring.)
In Markdown, one way of making a heading is to preface some text with #.
# Introduction (turns into <h1> in HTML)
## About markdown (turns into <h2>
In WordDown, to accomplish the same thing, the author uses the built-in heading styles - Heading 1 and Heading 2 respectively. These styles are the only widely-used standard way of structuring documents in the word-processing world - other elements such as quotes or lists have no equivalent standard implementations.
To make a block-quote in Markdown, you use a greater-than character:
> This is a block-quote.
In WordDown, just indent the paragraph either using the formatting tools on the Word ribbon, or define a style - but (at this stage at least) the WordDown processor does not use style names other than for detecting some headings; it uses indenting. So any indented style which is not a list or a heading will be treated as a block-quote.
The algorithm WordDown uses is being documented on the Google Code site, initially via the code. In essence, it is designed around the assumption that the user wants to create clean HTML, not to recreate the look of a paper document. So in a similar way to the light-weight wiki mark-up languages, it uses formatting and indenting as structural cues. The main device used is to look at the left margin:
- With a plain paragraph that is not a heading or a list item, an indent greater than the preceding non-heading paragraph means block-quote.
- Paragraphs in a monospace font are mapped to the <pre> (pre-format) element.
Features Summary
WordDown has the following features which are described in greater detail on the Google Code site for the software [2].
- Creates HTML from Word documents saved using "Save as HTML..." on Word for Windows versions from 2000 to 2010. The code runs in a Web browser and is packaged both as a bookmarklet and as a small Python Web server that users need to run from their documents directory.
- Works with Zotero citations and embeds them in-line using best-practice Scholarly HTML5 conventions.
- Can create rich semantic HTML5 with embedded microdata, given microformats in the source document.
Demonstration: Screenshots
The simplest way to run WordDown is to save documents manually as HTML, load them into a Web browser and use the WordDown bookmarklet as documented on the Google code wiki. A slightly easier workflow (which is harder to set up) is to run the WordDown server:
Figure 1. Browsing local files using the WordDown Web server.
When the user selects a word document, the WordDown server runs Microsoft Word in the background, saves the document as HTML, inserts Javascript into the head and serves the result back the user's browser. The result is that the user is presented with an HTML version of the Word document using a stylesheet derived from the one used by the W3C for its standards documents:
Figure 2. A Word document (this one) converted to HTML5 by WordDown running the browser.
The resulting document is HTML5 - and can be saved by the user for reuse. Alternatively, using another JavaScript application developed for the JISC HTML5 Project, parts of the document can be copied and pasted via the Show5ource bookmarklet.
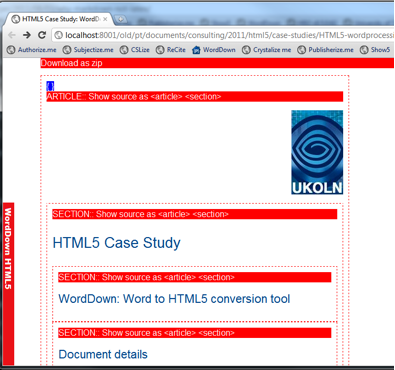
Figure 3. The Show5 bookmarklet.
In Figure 3 the Show5 bookmarklet identifies the HTML5 sections in a document and lets the user click to see copy and paste-ready source, or grab the whole document as a Zip file with all images.
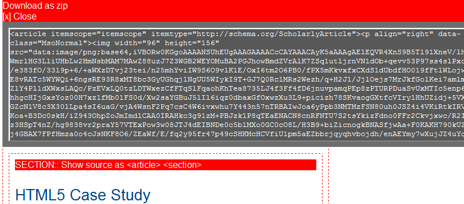
Figure 4. Show5 encodes image data in dataURIs to entire Web pages which can be copied and pasted, for example into a CML (corporate multi-lingual) such as WordPress.
Finally, the tool can create semantically rich documents. Here is the JSON format data which can be extracted from the page by clicking on the {} link:
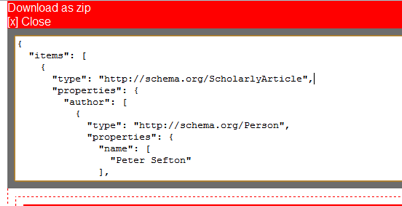
Figure 5. JSON format data which can be extracted from the page by clicking on the {} link.
This data was embedded in the document details table, using a microformat-like technique which is documented on the Google Code wiki.
Demonstration Web Documents
Demonstration documents in Word format (as noted above) that can be automatically transformed to HTML5 with embedded document semantics and re-processable citations can be found in the Google Code repository [3].
4. Impact
This work has had no impact so far as it is very new, but could be important to the uptake of HTML5 in academia if it is picked up by user communities, such as, for example, the authors who publish to KnowledgeBlogs, or agencies such as UKOLN involved in publishing a variety of academic materials.
To have a substantial impact, there would need to be a driver for people to create HTML5 materials for academia. Except in pockets of activity (e.g. academic blogging) this is not currently the case. One current trend - the move to ebooks away from paper may finally tip the balance and have academic authors looking for tools that can create the HTML they need as the building block for epub and Amazon Kindle ebook publications.
This tool would need work to make it easier to deploy in academic contexts.
Of course, an official HTML and/or EPUB plug-in from Microsoft itself working along similar lines could make this work obsolete overnight.
5. Challenges
The biggest challenge in this project has been the cross-site scripting rules in Web browsers which prevent code from accessing certain domains. In this case, if the Word document is loaded from the local file system, code in the browser may not access images from the local file system - this means the plug-in is prevented from doing any processing on images, such as creating data URIs, or creating a zip file of the entire document with all its images. To get around this, a simple Web service was created using Python, repeating a design pattern used in a previous project, the Integrated Content Environment (ICE) [2] which used a local Web server on users' machines to convert office documents to HTML. At the moment, this Web server is only suitable for use by technically adept users who can install Python 3 and run it, as well as download the source code, but it could be packaged as a Windows executable, were appropriate resources available.
6. Conclusions
The WordDown application shows that:
- The JQuery framework in a modern HTML5 browser is a very powerful document-processing language. When Word 2000 was released, it was unthinkable that a browser-based conversion system could be written in a few hundred lines of code.
- Using very simple heuristics borrowed from lightweight wiki mark-up languages, it looks feasible to produce high-quality semantically rich HTML5 materials with a minimum of training for authors, if they can be persuaded that most formatting will be discarded, and only structurally meaningful formatting will be kept.
Where academics are using the Web, and care about producing well structured resources, as with a growing cohort of academic bloggers and scholars embracing the 'Beyond the PDF' movement (whether they know it or not), it should be possible to introduce a tool such as WordDown into the tool chains supplied by supporting institutions.
A small investment in frameworks to support users wishing to run this kind of code could dramatically reduce production costs for HTML5 and EPUB e-book resources, by giving authors and editors tools to create resources straight from the tools they know best, such as MS Word.
7. References
[1] Word to XML and back again Sefton, P. O'Reilly, XML.com. December 8, 2004. http://www.xml.com/pub/a/2004/12/08/word-to-xml.html
[2] The integrated content environment. In AUSWEB 2006. Noosa: Southern Cross University. Sefton, P. http://eprints.usq.edu.au/archive/00000697/01/Sefton_ICE-ausweb06-paper-revised-3.pdf.

