Author: Mark MacGillivray
HTML5 Case Study 4: Visualising Embedded Metadata
1. About This Case Study
HTML5 case study on "Visualising Embedded Metadata" by Mark MacGillivray
This case study addresses ways of enhancing the dissemination and discoverability of research outputs. The sector had some success in making bibliographic metadata available on a large scale [1] [FN1] [FN2], and we must now demonstrate ways for individuals and small groups to interact easily and usefully with the data, in order to show the benefit of open bibliography and open publishing in general.
The opportunity to increase disseminability and discoverability to a significant degree has existed since the invention of the Internet, and which in technical terms may be termed a problem solved. However, a technical solution is only truly effective in the view of potential adopters if they are able to make use of it. Moreover, whereas some in the academic community have been comfortable using the Internet to distribute their research since the early 1990s, many more are not. Over the intervening years, the development of the standards on which the Internet is based have driven a vast improvement in usability and interoperability, opening it up to wider audiences, and triggering a shift towards online software services. This case study will demonstrate some of what can now be achieved using current open standards such as HTML5 [2] and [3] [FN3].
The demonstrations in this case study will be relevant to anyone that wants to do more with metadata; from students to lecturers and research group leaders, or administrators curating a publication list for a department or research assessment exercise, or those that support such activities through technical service provision. Overall outcomes will provide useful information for policy makers on how to support their community sustainably in years to come.
What Is Covered
The focus is on making data useful on the Web, and this will be achieved through embedding and visualisation techniques.
Embedded Visualisations
The report demonstrates the use of embedded visual representation using the D3 Javascript library [FN4], utilising Scalable Vector Graphics (SVG) HTML objects embedded directly into the Document Object Model. Note that although Canvas forms part of HTML5 specification, SVG is actually separate; however it is only via HTML5 that it has become possible to embed SVG elements directly in a document. Cross- and legacy-browser support issues are described.
Embedded Metadata
Whilst the initial demonstration will present visualisations of JSON data retrieved from a web service, secondary examples will show the use of embedded metadata for driving visualisations. This will build on the work of Adams [3] and Sefton [4], taking their recommendations on how to embed the metadata and convert to JSON for visualisation.
What Is Not Covered
There are many more possibilities with HTML5 and open Web standards not covered here [FN5] [FN6]. Further investigation relevant to this case study could include the use of storage and editable content to improve user experience greatly, and could combine with off-line material to provide a tool that could be used to create and manipulate documents and collections regardless of Internet connectivity; also postMessage could be used in place of traditional AJAX calls, which could reduce cross-domain security and interoperability problems in the long term.
2. Use Case
There are a number of potential use cases to which this case study could apply, as it is applicable to anywhere that a collection of data could be shared online. The particular example in this case is a small research group wishing to share its publications online.
A typical traditional workflow for achieving this might include researchers managing their own collection in their preferred format (or in some cases, not managing it at all), and an administrative officer collecting all the data together in one central location, such as a spreadsheet. This laborious and error-prone task would be further complicated by either upload of a static snapshot of the data (rendering it a legacy representation) or a manual re-entry of data into, for example, HTML files or perhaps a Content Management System - again introducing potential error, additional workload, and the requirements of regular maintenance.
The indirect costs of this workflow include the need for a method by which to make the content available. This traditionally could include the cost of running servers and Internet connections, or perhaps the cost of publishing and distributing the reference collection. It also involves significant cost in terms of staff expertise - an administrator with social and technical skills is required to collect and distribute the data, for example. In some cases, these demands can present a barrier to discoverability and disseminability.
The key facets of this use case are:
- Managing a dataset at a personal level - a bibliographic metadata collection
- Formatting and combining this dataset with others, to form a coherent, valuable, larger representation
- Distributing the collection, for purposes of management, advertisement, reporting
- Making the content of the collection useful - making it applicable, understandable and navigable to a wider audience
As we have yet to achieve the potential of disseminability that the invention of the Internet afforded us, to what extent can HTML5 and related open Web standards help us achieve this use case and open these collections up to a wider audience?
3. Solution
The proposed solution to this problem involves employing a stack of open technologies to present a simple and valuable distributed service to the academic community that attracts users by offering reduced administrative overhead, lower risk of error, lower total cost, and greater functionality.
Sharing Collections
Rather than manually managing and editing a collection of bibliographic records, it can be uploaded and parsed from typical bibliographic formats such as bibtex via the BibServer open source software package [FN7]. This software can be run as an online service that provides RESTful access onto the uploaded dataset [FN8]. With a collection of records suitably available and accessible programmatically, we can go on to perform some interesting operations with it.
Improving search
The BibServer front-end can be used to present a collection as a Web page for easy viewing, which provides faceted browse of the content. In addition, FacetView [FN9] can be used to provide a jQuery [FN10] based front-end that can be embedded into any other Web page. This provides the opportunity to make a typically static reference list at the end of a document into something much more useful - a key feature of a document that affords greater understanding and easier further investigation. It is also possible to make the reference list itself interactive - so rather than manually maintaining the list with the document, it can be managed via BibServer and embedded into the document via AJAX [FN11] - both as a complete list and as individual references within the text [12].
Although the BibServer example makes use of modern open Web standards, it is not explicitly reliant on HTML5. However, we can investigate further.
Data Anywhere
The critical aspect of the BibServer software is that it is built to assume that data is and should be stored and available from anywhere - it is not designed as a tool for collecting up and controlling all this data, either technologically or legally. Whilst BibServer can provide a service to convert and store datasets, it leaves users free to present that data anywhere they wish - on any departmental Web page, or on any course materials Web page. For example, a student can embed a browsable interface to their collection of references directly in their self-published research article on a Web site.
In addition to retrieving and operating on data from any source, and to embed the output of those operations on any web document, we can use HTML5 standards to embed the metadata itself in a page.
Embedded Metadata
The previous example demonstrates references from a remote collection being used within the text - all the reference links, and the reference list at the bottom of the piece, are inserted via jQuery. However, with HTML5 metadata standards such as scholarly HTML[FN13] and schema.org[FN14], the collection itself can be embedded within a document. By writing a parser for the recommended version of this embedded metadata, we can extract a collection from a document into a BibServer instance, and, in return, provide the embeddable references and faceted browse.
Sam Adams investigated the metadata standards available in HTML5 and made an example as part of his case study that could ingest PloS articles [FN15] and display them as HTML5 with embedded metadata [FN16]. His example shows a citation list embedded in a document in the schema.org format:
itemtype=”http://schema.org/ScholarlyArticle” itemscope=”" itemprop=”
http://purl.org/ontology/bibo/cites“>
<a name=”pone.0022199-deQueiroz1″></a>1.
itemtype=”http://schema.org/Person” itemscope=”" itemprop=”author”>de Queiroz, K
(1998) “itemprop=”name”>The general concept of species, species criteria, and the process of speciation: a conceptual unification and terminological recommendations.”
<em itemprop=”http://example.net/journalTitle”>Endless Forms: Species and Speciation
edited by itemtype=”http://schema.org/Person” itemscope=”" itemprop=”editor”>Howard, DJ; Berlocher, SH
itemprop=”http://purl.org/ontology/bibo/pageStart“> 57-itemprop=”http://purl.org/ontology/bibo/pageEnd“> 75</span>.
</p>
Figure 1. Sample citation in schema.org format.
This embedded metadata forms part of the Document Object Model (DOM), and as such it can be easily parsed out using Javascript / jQuery and converted to JSON:
{
“citekey”:”pone.0022199-deQueiroz1″,
“editor”:["Howard, DJ","Berlocher, SH"],
“author”:["de Queiroz, K"],
“title”:”The general concept of species, species criteria, and the process of speciation: a conceptual unification and terminological recommendations.”,
“journal”:”Endless Forms: Species and Speciation”,
“pages”:”57 to 75″
}
Figure 2. schema.org metadata parsed to JSON.
With the metadata readily available[FN17], it can be submitted to bibliographic metadata services for use in collection management, faceted browse, and visualisation generation.
Visualising the Data
With programmatic access to a collection, it is possible to increase the impact and usability of the collection considerably via a graphical user interface to the dataset, allowing for real-time display and manipulation of the dataset. This functionality becomes available by utilising open standards for embedding the metadata and remotely querying services that can act on the metadata collections.
By querying the same API as the faceted browse front end and retrieving the required information about the collection, SVG visualisations can be prepared using the D3 Javascript library. This visualisation can also be embedded within the document.
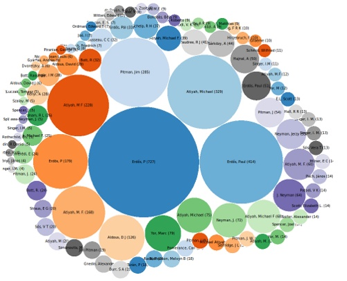
Figure 3. Visualisation generated from bibliographic metadata embedded in a Web page.
It is possible to alter the visualisation based on search parameters - it is not a pre-processed image, but an embedded representation of a current view on a dataset[FN18]. Although it has not been demonstrated in this case study, these visual representations can be further enhanced to work as access methods onto the data too - for example, discovering the most popular author via the visualisation could trigger faceting of the dataset on that author name, and so on. Work into this is ongoing on the BibServer Project.
4. Impact
By combining these examples it is possible to provide an enhanced user experience and improved accessibility and disseminability by making data easier to discover and use.
To take advantage of this, all that is required is the addition of a few lines of Javascript to a page. To demonstrate, an example has been created that performs the following:
- Take a sample page with embedded metadata from the HTML5 app created by Sam Adams
- Parse the page for embedded metadata
- Submit the metadata to the remote BibSoup service for indexing and collection creation
- Query the collection for facet information
- Generate a visualisation using D3 of the facet information
- Embed the visualisation as an SVG on the page
This is available to view at http://test.cottagelabs.com/html5 [FN19].
If Sam Adams wished to add this functionality directly to his HTML5 app [4], or if others wanted similar functionality on their Web pages, it would require the addition of only a few lines of javascript and suitable embedded metadata.
This solution makes use of HTML5, CSS, javascript and jQuery to provide an example of what is possible now. It is already possible to build and manage an authoring and distribution tool for education and research, and standards such as HTML5 bring us closer to making such a tool available to the diverse audience of people involved in the education and research community.
With sufficient resolve, we could abandon restrictive licensing of research output and move instead to a model of open scholarship supported by open source software built on open web standards, saving billions for the research and education community and making its valuable output accessible to all. To do so, we need to overcome only a few problems.
5. Challenges
Cross-browser Compatibility
Although HTML5 has been in development for a number of years, adoption by the major browser vendors is recent and patchy. Whereas recent versions of Firefox have supported HTML5 [20], Internet Explorer in particular (and as usual) was slow to support HTML5, although Microsoft are now officially backing the standard and newer versions should meet specifications. As Internet Explorer is still the most popular browser, despite being the least s tandards-compliant, some trickery is required to support HTML5 on older but nonetheless common versions. Table 1 below details the recent versions of most common browsers with which this study's solution is compatible.
| Browser | Version | Working? |
|
Firefox |
7.0.1 |
Yes |
|
Opera |
11.10 |
No - AJAX error |
|
Safari |
5.0.4 |
Yes |
|
Internet Explorer |
8.0.6001.18702 |
No - AJAX access denied error |
|
Chrome |
13.0 |
Yes |
Table 1. Compatibility of solution with recent versions of common browsers.
The errors listed in the table above could most likely be resolved on these browsers, and are unlikely to have arisen specifically due to errors in HTML5, but, rather, due to differences in how browsers parse Javascript, perform cross-domain requests, and so on. Further work will continue on this. This demonstrates the difficulties that should be considered when using these or any new technologies and standards - adherence and purposeful non-adherence begin to compete with one another as successful strategies.
Of course, a great advantage of open standards and open source development is that there are many other people in the world tackling the same problems. Thus, it is easy to find readily available solutions to such problems, such as HTML5 shim [FN21] and Modernizr [FN22].
Reliance on Javascript
Javascript used to be considered secondary to the function of web pages and making a page that relied on Javascript was considered bad form. However, it is now virtually impossible to find a user that does not have Javascript enabled, as all browsers fully support it. Whilst it is possible to turn off Javascript, this is most likely only going to happen in the case of a user who understands the impact turning it off will have. The only exception to this is disability - where a user may be visiting a Web page via screen-reading software for example, lack of Javascript support can still cause problems. Thus we must be careful to balance increased functionality with graceful degradation - where Javascript supports enhancements for the typical user, the page should still provide useful content for users accessing it via alternative technologies.
Flash, SVG or Canvas
There are examples of HTML5 being used by technologies and businesses that rely on their online functionality to work appropriately across all browsers [6]. Whereas Flash is an old standard, it is proprietary and has suffered from the fact that content embedded in a Flash object is removed from the rest of the document. Since Apple, for one, has refused to support Flash on its devices, directly embedded visualisations are more appealing.
Staff at Slideshare recently completed a large project to convert their online presentations to HTML5, successfully overcoming many compatibility problems in the process (SlideShare Engineering Blog, 2011). They are now moving all their legacy Flash presentations to HTML5, but will continue to support legacy formats where necessary. However this commitment, along with some other impressive examples of what can be achieved [FN23] [FN24], show that the move is certainly towards the HTML5 method of direct embedding. Debate continues as to whether SVG or Canvas is most appropriate [FN25], and to some extent, it depends on application - and there are already ways to convert between them [FN26]. This is an issue to keep under observation.
The Meaning of Open
The most valuable thing we can learn from open Web standards is the open part; it is not impossible to build a working technology and community around a freely available resource, it is not impossible to disseminate our research output freely to everyone in the world (bar the costs of delivery itself); but achieving this requires change and effort.
6. Conclusions
HTML5 and open web standards are already being put to good use. The ethos of open standards is highly appropriate to the education and research community, and the only complexity in using them to their full advantage is that of poor adherence to the standards. Therefore, where a particular software / technology creator deliberately fails to implement those standards appropriately, it should be recognised as detrimental to the purpose of our community.
Given that the Internet was invented by a researcher to make it easier to disseminate research outputs and given the cost of traditional (and less functional) publication, it should be obvious that supporting open web standards is absolutely crucial to the future of the academic community. The risk represented by facing the aforementioned compatibility challenges is nothing compared to that of failing to support these standards in future.
References
[1] Final product post: Open bibliography. Project report. [Web log message]. MacGillivray, M. (2011). http://openbiblio.net/2011/06/30/final-product-post-open-bibliography/
[2] HTML is the new HTML5. The WHATWG Blog. Hickson, I. 2011. http://blog.whatwg.org/html-is-the-new-html5
[3] HTML5: A vocabulary and associated APIs for HTML and XHTML. Editor’s Draft, January 10, 2012. W3C. (2012) http://dev.w3.org/html5/spec/Overview.html
[4] Semantics and Metadata: Machine-Understandable Documents. Adams, S. 2012. HTML5 Case Studies, UKOLN, University of Bath.
[5] Conventions and Guidelines for Scholarly HTML5 Documents. HTML5 Case Studies, Sefton, P. 2012. UKOLN, University of Bath.
[6] Using HTML5 to transform WordPress' TwentyTen theme. Smashing Magazine. Shepherd, R. 22 February 2011. http://wp.smashingmagazine.com/2011/02/22/using-html5-to-transform-wordpress-twentyten-theme/
[7] SlideShare ditches Flash for HTML5. SlideShare Engineering Blog. 27 September 27 2011, By JON [Web log message]. http://engineering.slideshare.net/2011/09/slideshare-ditches-flash-for-h...
Footnotes
[FN1] JISC Open Bibliography project blog http://openbiblio.net
[FN2] Open Bibliographic Principles http://openbiblio.net/principles
[FN3] HTML5 introductory presentations http://www.slideshare.net/html5
[FN4] D3 javascript library- d3.js http://mbostock.github.com/d3/
[FN5] HTML5 demos http://html5demos.com/
[FN6] HTML5 doctor http://html5doctor.com/
[FN7] BibServer Project http://bibserver.okfn.org
[FN8] An example BibServer instance http://bibsoup.net/
[FN9] Facetview http://github.com/okfn/facetview
[FN10] jQuery http://jquery.org
[FN11] AJAX explanation http://en.wikipedia.org/wiki/Ajax_%28programming%29
[FN12] A document with embedded references http://cottagelabs.com/phd
[FN13] Scholarly HTML, http://scholarlyhtml.org/
[FN14] Schema.org, http://schema.org/
[FN15] Public Library of Science, http://plos.org/
[FN16] Sam Adams (2011), HTML5 App, http://html5app.bluefen.co.uk/
[FN17] Sample schema.org metadata retrieved from html5app and converted to JSON, http://test.cottagelabs.com/html5/records.json
[FN18] Example generation of visualisations via D3 javascript library from records stored on BibSoup http://test.cottagelabs.com/d3
[FN19] Example parsing metadata from Sam Adams HTML5 app output, submission to remote BibSoup service, query and visualisation http://test.cottagelabs.com/html5
[FN20] Firefox announces HTML5 support http://hacks.mozilla.org/2010/05/firefox-4-the-html5-parser-inline-svg-s...
[FN21] HTML5 shim, http://code.google.com/p/html5shim/
[FN22] Modernizr, http://www.modernizr.com/
[FN23] Embedded presentations, http://sozi.baierouge.fr/wiki/doku.php?id=en:welcome
[FN24] Embedded draw, http://bomomo.com/
[FN25] SVG vs Canvas debate, http://stackoverflow.com/questions/568136/svg-vs-canvas-where-is-the-web-world-going-towards
[FN26] SVG to Canvas conversion, http://plindenbaum.blogspot.com/2009/11/tool-converting-svg-to-canvas%5F22.html

